

In the previous post I mentioned that t-tests are used to compare two means in order to reveal whether they are significantly different. In order to transform the means into t-scores and perform the mean comparison, t-tests are conducted. There are two kinds of those: between-subjects and within-subjects, depending on the measure design of an experiment (I will elaborate on this and give you some examples further down).
In this post, I will talk about within-subjects tests, their assumptions, calculation and significance testing. Before that though, I will quickly explain the difference between Parametric and Non-Parametric Statistics tests.
In this post, I will talk about within-subjects tests, their assumptions, calculation and significance testing. Before that though, I will quickly explain the difference between Parametric and Non-Parametric Statistics tests.
Parametric v Non-Parametric Tests
When it comes to statistics, the first thing to decide is which type of test to implement: Parametric or Non-Parametric. This is quite straightforward:
a) Parametric Tests are used when the data is normally distributed and when it is interval or ratio.
b) Non-Parametric Tests are used when the data is NOT normally distributed and when it is ordinal.
And this is it! So the only thing you need to do is to check the distribution and the measurement type of your data, and you will know which type of test to use. However, whatever type it is you choose to use, there is yet another decision to be made: whether to implement within-subjects or between-subjects design.
a) Parametric Tests are used when the data is normally distributed and when it is interval or ratio.
b) Non-Parametric Tests are used when the data is NOT normally distributed and when it is ordinal.
And this is it! So the only thing you need to do is to check the distribution and the measurement type of your data, and you will know which type of test to use. However, whatever type it is you choose to use, there is yet another decision to be made: whether to implement within-subjects or between-subjects design.
Within-Subjects v Between-Subjects tests
Next thing you need to decide is whether your experiment design within-subjets or between-subjects one in order to choose an appropriate test for comparing sample means. This is also quite simple:
a) Within-subject design involves repeated measures of the same sample. In other words, the same participants are tested in different conditions/at different points in time. Example of an experiment could be, say, does memory decrease after frontal lobotomy? Clearly, we would have to test the same patients to find out: before and after the surgery. It is also used when there is no opportunity to have a control group due, for example, to a rare condition/illness.
b) Between-subjects design is all about measuring different groups of participants. So, for example, do bilingual children have a better memory? Obviously, the same child can not be bi-lingual and not bi-lingual at the same time, so we would need to test two different groups and then compare the results. In medical research, we would use this test to compare those who undertook a treatment and those who did not (control group).
a) Within-subject design involves repeated measures of the same sample. In other words, the same participants are tested in different conditions/at different points in time. Example of an experiment could be, say, does memory decrease after frontal lobotomy? Clearly, we would have to test the same patients to find out: before and after the surgery. It is also used when there is no opportunity to have a control group due, for example, to a rare condition/illness.
b) Between-subjects design is all about measuring different groups of participants. So, for example, do bilingual children have a better memory? Obviously, the same child can not be bi-lingual and not bi-lingual at the same time, so we would need to test two different groups and then compare the results. In medical research, we would use this test to compare those who undertook a treatment and those who did not (control group).
Student's t-test for related samples
This test is parametric (meaning, is performed when the data is ratio or interval and is normally distributed) and is for a within-subjects design (in other words, for related samples). It looks at differences between pairs of scores (Condition 1 and Condition 2). Because the pairs of scores come from the same participants, the individual differences are eliminated, and any differences in scores only reflect the effect of experimental manipulation.
EXAMPLE
Within subject study on the effect of frontal lobotomy on memory: does memory decreases after the surgery?
Null hypothesis (Ho): there is no effect of frontal lobotomy on the memory. Ho predicts that the mean of the two samples (Before the lobotomy, After the lobotomy) will be identical, and they are drawn from the same population.
Alternative hypothesis (H1): there is an effect of lobotomy on memory. H1 predicts that the two samples (before and after the lobotomy) will have different means, thus these samples come from two different populations with different characteristics.
Independent Variable: lobotomy
Dependent Variable: scores on memory test
To answer the question of the research we need to compare the means of the two samples and find whether there is a significant difference between the two. To do so, we use the Student's t-test for related samples (parametric test because the data is numerical (scores on memory tests) and within-subjects design because we test the same participants). The calculation for the Student's t-test for related samples is as follows:
EXAMPLE
Within subject study on the effect of frontal lobotomy on memory: does memory decreases after the surgery?
Null hypothesis (Ho): there is no effect of frontal lobotomy on the memory. Ho predicts that the mean of the two samples (Before the lobotomy, After the lobotomy) will be identical, and they are drawn from the same population.
Alternative hypothesis (H1): there is an effect of lobotomy on memory. H1 predicts that the two samples (before and after the lobotomy) will have different means, thus these samples come from two different populations with different characteristics.
Independent Variable: lobotomy
Dependent Variable: scores on memory test
To answer the question of the research we need to compare the means of the two samples and find whether there is a significant difference between the two. To do so, we use the Student's t-test for related samples (parametric test because the data is numerical (scores on memory tests) and within-subjects design because we test the same participants). The calculation for the Student's t-test for related samples is as follows:
 |  |
Average Difference Score is found by calculating the differences between the pairs of scores (X1-X2), and then finding their mean (by summing them up and dividing by their number).
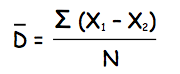
Estimated Standard Error of the average difference score is calculated with the same Standard Error formula that we have used before. Firstly, calculate the Estimated Standard Deviation (SD) of the difference between the sample means:
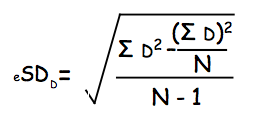
Now, calculate the Estimated Standard Error of the differences by dividing SD by the square root of their number:
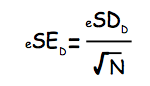
To get the t-value, divide the average difference score by the estimated standard error of the differences.
There you have it! Although it all seems like a notorious process, the math is actually quite simple and only features the formulas we've covered before: mean, Standard Deviation and Standard Error.
There you have it! Although it all seems like a notorious process, the math is actually quite simple and only features the formulas we've covered before: mean, Standard Deviation and Standard Error.
Degrees of Freedom and Significance Testing
Degrees of Freedom (DF) show how many scores can vary without changing the sample mean. For the related samples test, Degrees of Freedom are simply equal to N - 1 (where N is the number of participants, or, pairs of scores).
To test your results for the significance, you need to calculate the t-value and degrees of freedom, and then set the significance level (normally p<0.05). Basing on the p value and DF, use the significance table to find the critical value; then look at your t-value.
If +t > + critical value or -t < - critical value, we can accept the H1. It means that there is a statistically significant difference between the means of the two samples, and that this difference falls in the 5% of the extreme cases.
For example, imagine you have 10 participants. Degrees of Freedom in this case would be 10-1 = 9. Say, your t-value is 2.04, and you need to know whether this difference is significance at the 5% significance level. Look at the table below:
To test your results for the significance, you need to calculate the t-value and degrees of freedom, and then set the significance level (normally p<0.05). Basing on the p value and DF, use the significance table to find the critical value; then look at your t-value.
If +t > + critical value or -t < - critical value, we can accept the H1. It means that there is a statistically significant difference between the means of the two samples, and that this difference falls in the 5% of the extreme cases.
For example, imagine you have 10 participants. Degrees of Freedom in this case would be 10-1 = 9. Say, your t-value is 2.04, and you need to know whether this difference is significance at the 5% significance level. Look at the table below:
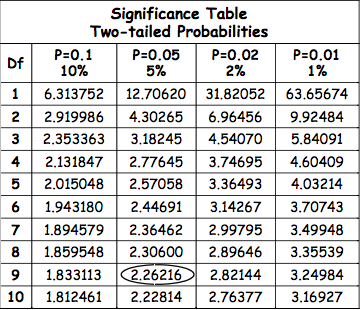
We can see, that with the Degrees of Freedom = 9, the critical value is 2.26. Our t-value is 2.04, which is NOT larger than the critical value. Therefore, the difference that we found is NOT statistically significant.
