
| Distribution tells you the occurence frequency of any particular score in your data; I have talked about this idea in earlier posts. However, today I will look into the different distribution curves that can be used to represent frequency. The essential concept which allows us to make sense of these curves is z-scores. I will show how to calculate those and what they tell about the data. | 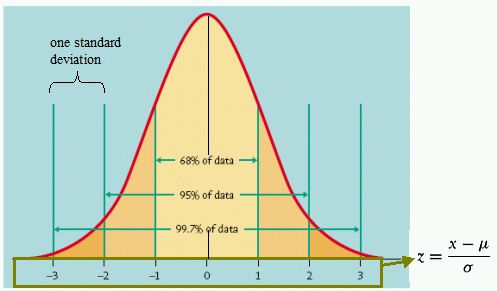 'Normal' distribution |
|
0 Comments
Basics: Dispersion (Variability) of data: Deviation, Variance, Standard Deviation. With video!9/12/2012  Previously, I talked about the mean, median, mode and outliers which described our data in terms of its central tendency. Today I will cover the idea of Variability, or Dispersion. There are three concepts which allow us to determine it: Deviation, Variance and Standard Deviation. There is also such thing as a Standard Deviation, which I will cover in the next post. There are also two great video lessons made by Khan Academy, which explain variance in a very easy to follow and entertaining way. Variability In descriptive statistics, there are three concepts which help us describe our data: central tendency (how typical it is), dispersion (how varied it is) and distribution (how data is distributed). In this post I will talk about the central tendency, in other words, determining the AVERAGE of your data. I will discuss three main concepts here: mean, median and mode. I will also discuss the mild and extreme outliers and explain the tricky procedure of identifying them. They actually describe dispersion of data, but because finding them involves some operations with the mean, I decided to show it in this post.  In this article I will talk about the concept of frequency and percentage frequency, and then explain how to use charts and diagrams to illustrate them: pie and bar charts for nominal and histograms - for numerical data.
Frequency tells us how often some category occurs in our data. It is important to understand that the category can have either nominal or numerical value. With nominal ones it is quite straightforward: for example, if there are four people with blue eyes in a room of 12 people, then it means that the frequency of blue-eyed people in this room is four. Here, the category is blue eyes (in this data other categories could be, for example, green, brown and grey eyes).  It is important to know which type of measurement to use in your research/experiment and not to confuse those types. Normally we would talk of Numerical (Score) and Nominal (Category) types of measurement; numerical then can be of three types itself: ordinal (rank), interval and ratio measurement types.  Importance of statistics explained The first concept that I want to discuss is variable. It is quite a simple concept, but due to its numerous types it might become confusing. I will discuss independent and dependent variables, extraneous variables (situational and participant), and confounding variables.
So, variable is anything that varies (changes or can be changed) - for example, a characteristic, value, time, number etc. In the majority of psychological experiments you will want to see whether a change in one thing (variable 1) causes any change in another one (variable 2) - and then interpret this dependency or its absence. |
